Tracking und KI
Seit KI zunehmend Einzug hält, sind auch Tracking-Lösungen immer stärker davon betroffen. Die Implikationen reichen von schädlichem, exzessivem AI-Crawling, das Server an den Rand ihrer Belastbarkeit bringt, über neue Auswertungsmöglichkeiten durch verbesserte Mustererkennung und die Transferleistung von Tracking-Daten in KI-Modellen bis hin zu Integrationen und Schnittstellen, die viele neue spannende Möglichkeiten eröffnen.
KI-Crawler verfälschen die Daten im Tracking
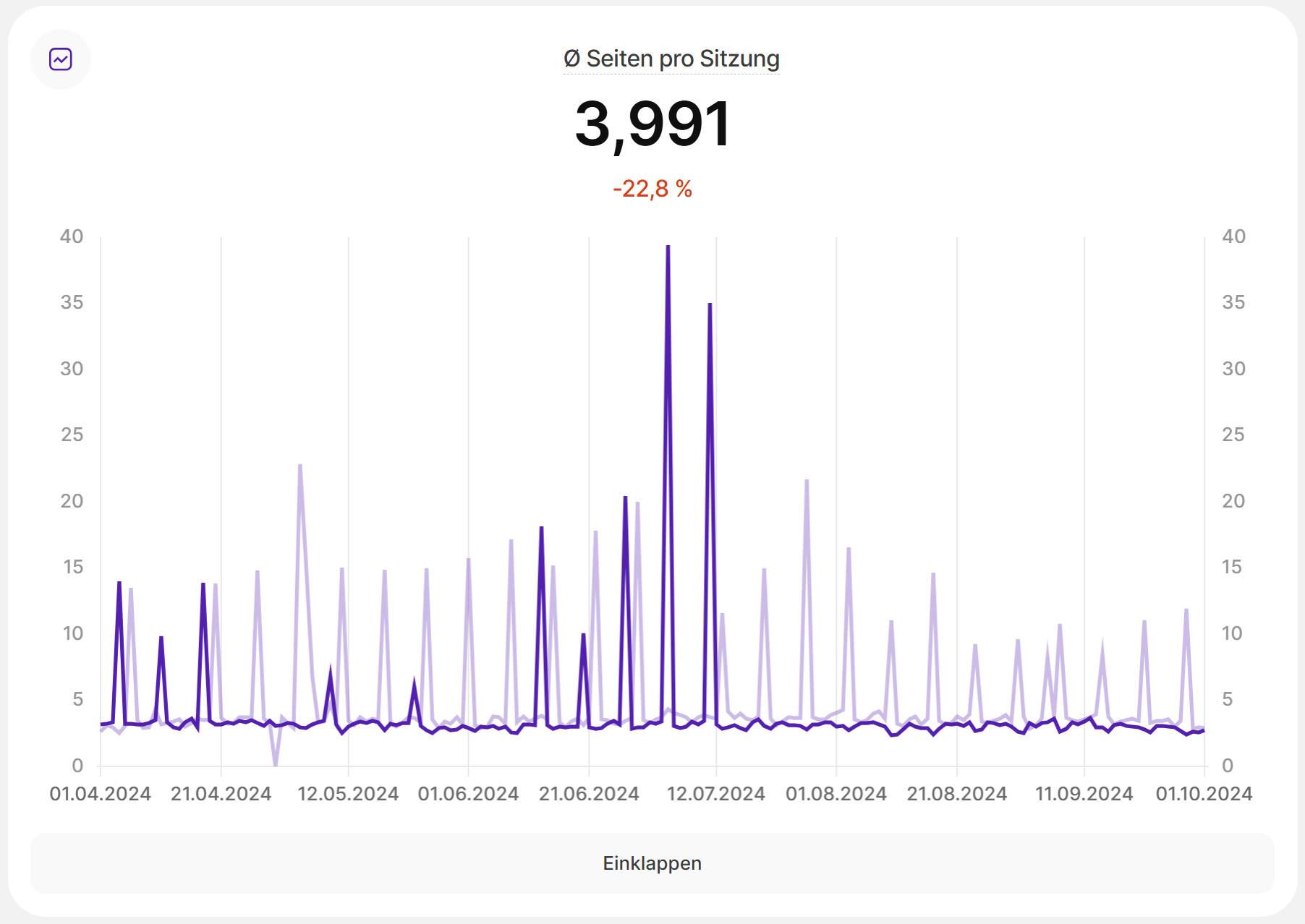
Zur Verdeutlichung: GoogleBot, GPTBot, ClaudeBot, AppleBot, und PerplexityBot usw. sind gemeinsam für 39% des gesamten Internet Traffics verantwortlich. Auf je drei menschliche Besucher kommen zwei Bots. Die Wahrheit ist zwar auch, dass der GoogleBot und BingBot noch immer die Majorität der Crawlinganfragen bestimmen, aber mit der zunehmenden Zahl an AI-Crawlern steigt auch die Gefahr von falschen Daten in Trackingtools. So dynamisch wie sich derzeit die Landschaft entwickelt und in der Geschwindigkeit, in der neue Crawler auf das Internet losgelassen werden, ist es schwer, als Toolanbieter mitzuhalten. Google Analytics nutzt zur Filterung ihre eigenen Research-Daten und eine Liste von IAB. Matomo schließt per Default User Agents aus, bei denen Javascript nicht aktiviert ist. Außerdem können Admins auch User Agents einzeln ausschließen. In LUX pflegen wir ebenfalls eine Liste der Bots, die vom Tracking ausgeschlossen werden sollen. Nutzer können diese Liste für ihre eigenen Projekte beliebig erweitern oder anpassen. Ein großer Vorteil von Open Source Tracking Tools, da hier transparent in den Quellcode eingegriffen werden kann und eine starke Community hinter den Projekten steht, die neue Bots meldet. So pflegt auch PostHog eine Liste der exkludierten Bots und die fleißige Community meldet neue Bots, die dann in die Liste aufgenommen werden. Natürlich lässt es sich nicht ausschließen, dass Daten durch Crawler verfälscht werden, aber auf solche fehlerhaften Daten schnell zu reagieren zeichnet eine gute Software aus. In dem Bild unten zeigt sich die Datenverfälschung durch einen wöchentlichen Crawler von Sistrix, der die Anzahl besuchter Seiten natürlich extrem verfälscht. Genauso wichtig ist aber auch zu erfassen, ob Crawler die Website besuchen können oder ob GoogleBot & Co. Hürden bei der Exploration der Informationen haben und dadurch die Sichtbarkeit bei Google, ChatGPT und Bing verhindert wird.
AI & SEO – „The Great Decoupling“
Googles AI Overviews hat die SEO Community aufgescheucht. Die Entkopplung der Klicks von den Impressions in den Ansichten der Google Search Console (GSC) wird inzwischen als „the great decoupling“ bezeichnet. Durch die AI Overviews sinkt die CTR signifikant, weil die AI Overviews viele Suchanfragen direkt beantwortet. Außerdem werden die Quellen kaum sichtbar angezeigt, wodurch der organische Traffic zusätzlich sinkt. In einigen Fällen zeigt sich bei besonders hochwertigem Content eine erhöhte Sichtbarkeit. Weil AI diesen Content für die Zusammenfassungen verwendet und dadurch Impressionen entstehen. Dieses „Content Scraping“ durch AI führt dazu, dass die hochwertigen Inhalte von primären Ressourcen (wie z.B. Hochschulen und Forschungseinrichtungen) ohne Namensnennung weiterverwendet werden. Es wird bereits verhandelt, ob dieses Vorgehen noch rechtskonform ist oder eine Urheberrechtsverletzung darstellt.
Auf SEOs kommen jetzt neue und zusätzliche Aufgaben für die Optimierung der Inhalte für diese AI Overviews zu.
Klar ist, dass sich die Abhängigkeit von SEO für Websites verändert, weil sich das Nutzerverhalten radikal verändert. Da sind natürlich auch Propheten, die regelmäßig den Tod von verschiedenen Themen postulieren, nicht weit. Performance-Marketing ist tot, SEO ist tot usw. Fakt ist: Nach wie vor ist Google der dominante Traffic Provider für viele Websites. Auf den TYPO3 Developer Days 2025 habe ich einen ausführlichen Vortrag über die aktuellen Entwicklungen und mögliche Maßnahmen gehalten.
Gerne zeige ich Ihrem Team in einer Schulung, wie Sie auf die Entwicklungen reagieren können.
First-Party-Daten
Tracking Consent wird teilweise durch "tracking prevention" von Browsern und Devices abgelöst, die Lebensdauer von Cookies beschränkt und Trackingpixel deaktiviert. Auch gegen Fingerprinting gehen Browser und das W3C Konsortium aktiv vor. Das ewige Hin und Her bei "third party data" von Google sorgt ebenfalls für Unsicherheit über die Zukunft der Webanalyse.
Aktuell geht der Trend zu First-Party-Cookies und Cookieless Tracking.
First Party Cookies werden von den Marktteilnehmern weiterhin als technisch notwendig und sinnvoll akzeptiert. Allerdings muss man sich durchaus die Frage stellen, ob Setups mit Stape.io (Serverseitiges Tagging, um die Tracking-Prävention von Browsern zu umgehen) wirklich im Sinne der DPA sind.
Lebhafte Diskussionen, wie mit den ständig steigenden Preisen von Werbenetzwerken umgegangen werden soll, ändern nichts an der Notwendigkeit von einem akkuraten Tracking der Werbeausgaben. UTM-Parameter werden abgeschnitten, Cookies automatisch gelöscht und Fingerprints gefälscht. Das Versprechen von Google „KI wird das schon regeln“ erfüllt sich bislang nicht. Sonst würden sie nicht derart stoisch an den Third-Party-Cookies in Chrome festhalten.
Es bleibt ein „Katz-und-Maus-Spiel“.
Um damit umzugehen, empfehle ich ein möglichst flexibles, unabhängiges und agiles Tracking-Setup. Wer sich nur auf eine Lösung verlässt, kann von unerwarteten Störungen schmerzhaft getroffen werden.
Stellen Sie sich vor:
Sie arbeiten Wochen und Monate an einer teuren Werbekampagne, nehmen zehntausende Euro in die Hand und mitten in der Kampagne fällt das Tracking aus oder wird durch irgendwelche Crawler, KI-Agenten etc. gestört. Wer sich ausschließlich auf eine Lösung verlässt, hat schnell viel Geld zum Fenster hinausgeworfen.